Introduction
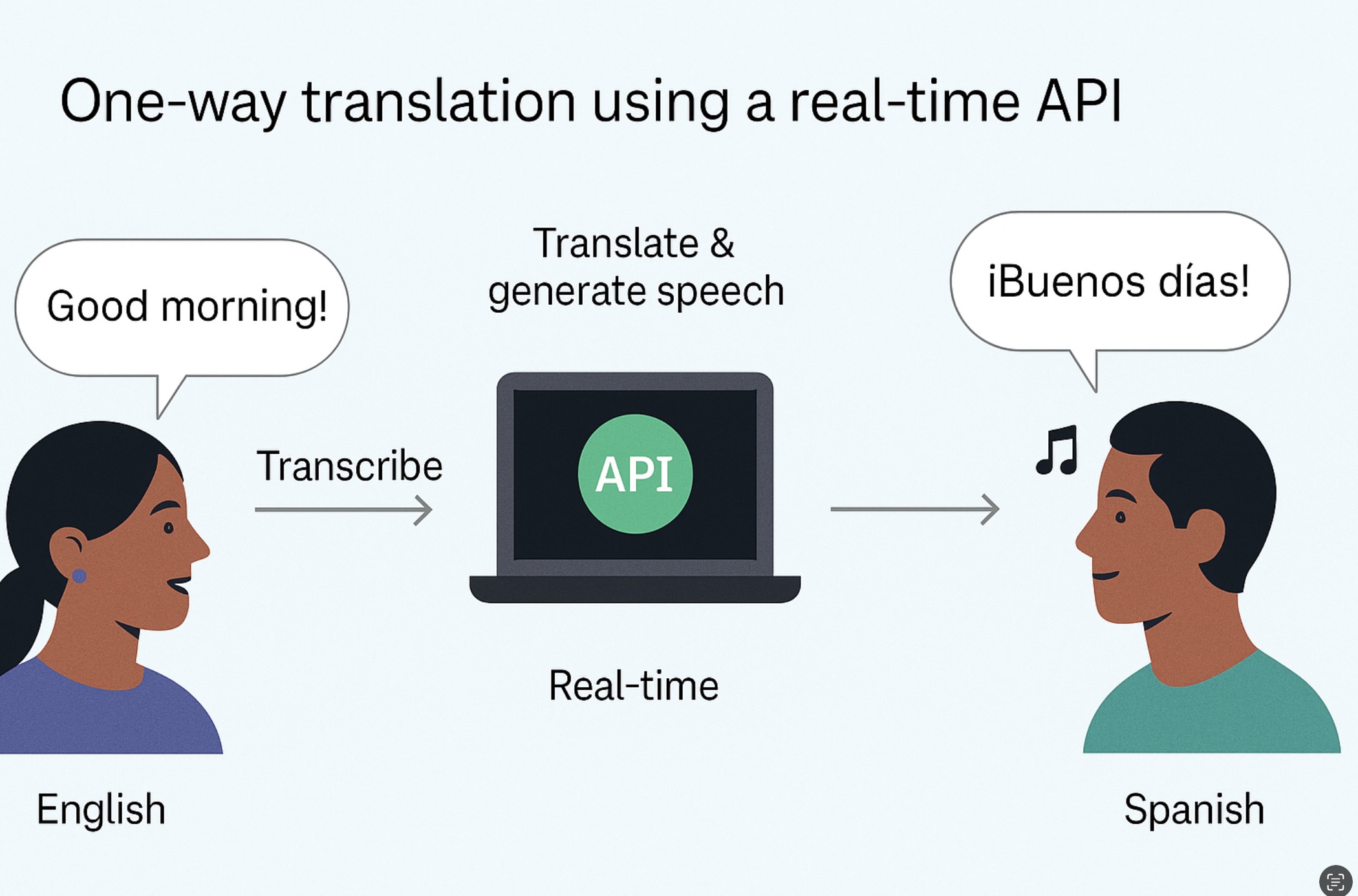
This guide shows how to build a simple one-way translator: the user speaks, your app streams audio to the Realtime API, you receive partial and final transcripts, translate them to the target language, and (optionally) synthesize speech. You’ll get an end-to-end skeleton you can adapt for customer support, learning tools, kiosks, or travel apps.
Architecture
High-level data path: Mic → WebSocket client → Realtime API (ASR) → text → translation → output (text or TTS).
Setup
- API Key: store your key in a server environment variable (never ship it in client code).
- Backend token endpoint: create a minimal API route that returns a short-lived token to the browser.
- Client permissions: ask for microphone access and capture PCM/Opus chunks.
import express from 'express';
const app = express();
app.get('/api/realtime-token', (req, res) => {
// Issue a short-lived token your client can use to connect to Realtime
const token = process.env.OPENAI_API_KEY; // ideally mint an ephemeral token
res.json({ token });
});
app.listen(3000, () => console.log('token server on :3000'));
Connect via WebSocket
async function connectRealtime() {
const { token } = await fetch('/api/realtime-token').then(r => r.json());
const url = 'wss://api.openai.com/v1/realtime?model=gpt-5-realtime';
const ws = new WebSocket(url, { headers: {
'Authorization': `Bearer ${token}`,
'OpenAI-Beta': 'realtime=v1'
}});
ws.onopen = () => console.log('WS connected');
ws.onerror = (e) => console.error('WS error', e);
ws.onclose = () => console.log('WS closed');
ws.onmessage = (ev) => handleRealtimeMessage(ev);
return ws;
}
Stream mic audio
Capture audio with getUserMedia, encode to PCM/Opus, and push small chunks for low latency.
async function startStreaming(ws) {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
const ctx = new AudioContext();
const src = ctx.createMediaStreamSource(stream);
const processor = ctx.createScriptProcessor(4096, 1, 1);
src.connect(processor);
processor.connect(ctx.destination);
processor.onaudioprocess = (e) => {
const data = e.inputBuffer.getChannelData(0);
// Convert Float32 PCM to Int16 little-endian and send
const buf = new ArrayBuffer(data.length * 2);
const view = new DataView(buf);
for (let i=0; i<data.length; i++) {
let s = Math.max(-1, Math.min(1, data[i]));
view.setInt16(i*2, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
ws.send(buf);
};
}
Translate & output
The server will emit interim/final transcripts. When you receive a final transcript, pass it through a translate call (model or endpoint of your choice). If your app needs spoken output, push the translated text into a TTS endpoint and play the resulting audio buffer.
function handleRealtimeMessage(ev) {
const msg = typeof ev.data === 'string' ? JSON.parse(ev.data) : ev.data;
if (msg.type === 'transcript.partial') {
updateUI(msg.text); // show partial
}
if (msg.type === 'transcript.final') {
showFinal(msg.text);
translateAndMaybeSpeak(msg.text, 'es'); // example target: Spanish
}
}
async function translateAndMaybeSpeak(text, target) {
// 1) Translate text (choose your translation model)
const translated = await translate(text, target);
// 2) Optional: TTS the translated string
const audio = await ttsSynthesize(translated, { voice: 'alloy', format: 'mp3' });
play(audio);
return translated;
}

Latency tips
- Use small chunks (e.g., 20–40 ms) to reduce end-to-end lag.
- Prefer binary frames for audio rather than base64 strings.
- Show partial results in the UI so the user sees progress.
- TTS only on final segments to avoid choppy audio.
Security
- Never embed your API key in the browser—use a server token exchange.
- Rate-limit the token endpoint and rotate keys regularly.
- Consider recording consent flows if you store audio/text.
Troubleshooting
- Silence only? Check microphone sampling rate and PCM conversion.
- WS closes? Inspect server logs; confirm headers and model query string.
- Choppy output? Increase chunk size slightly or debounce TTS.
Next steps
- Add language auto-detect and route to the right translation model.
- Buffer longer segments and stream a higher-quality TTS voice.
- Persist transcripts with timestamps for analytics.
You might also like